тема: Кодирование текстов. Равномерные и неравномерные коды
тема: Кодирование текстов. Равномерные и неравномерные коды







теория.
Для решения своих задач человеку часто приходится преобразовывать имеющуюся информацию из одной формы представления в другую. Например, при чтении вслух происходит преобразование информации из дискретной (текстовой) формы в непрерывную (звук). Во время диктанта на уроке русского языка, наоборот, происходит преобразование информации их непрерывной формы (голос учителя) в дискретную (записи учеников).
Кодирование текста – это процесс преобразования символов или слов в последовательность чисел или символов, которые могут быть сохранены, переданы или обработаны компьютером. Это важная часть работы с данными и информацией, особенно в цифровой среде.
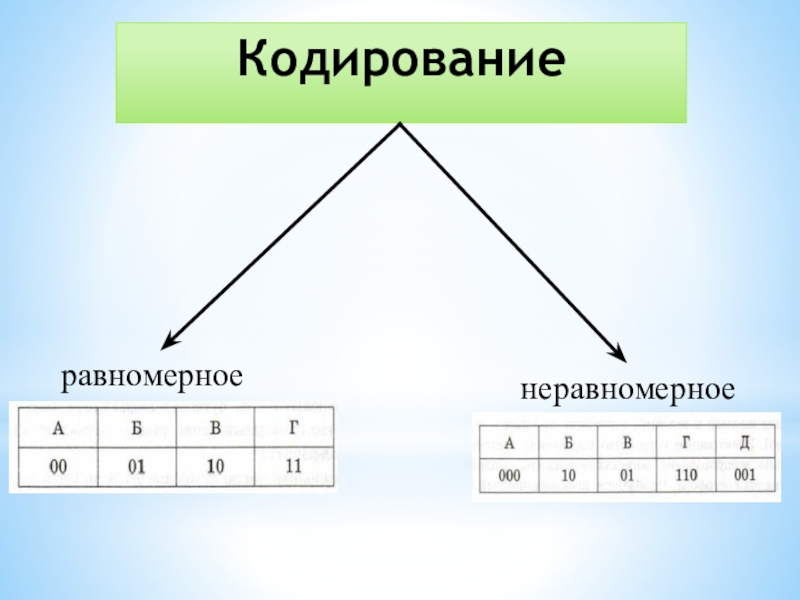
Различают равномерные и неравномерные коды. Равномерные коды в кодовых комбинациях содержат одинаковое число символов, неравномерные – разное.
Равномерные коды – это коды, в которых каждый символ или слово кодируются одинаковой длины строки. Например, ASCII – это равномерный код, в котором каждый символ кодируется 7-битным двоичным числом.
Неравномерные коды – это коды, где разные символы или слова кодируются строками разной длины. Примером может служить UTF-8, который является современным стандартом кодирования символов для Unicode. В UTF-8 символы могут кодироваться строками от 1 до 4 байтов, что позволяет использовать больше символов, чем в ASCII, сохраняя при этом совместимость с ним.
Декодирование сообщения - это обратный процесс кодирования, при котором закодированные символы или слова преобразуются обратно в исходные данные. Это важно для обеспечения того, чтобы информация, отправленная через различные каналы передачи данных, могла быть успешно получена и обработана получателем.